OpenStack
II Présentation d’une solution cloud : OpenStack
II-1 C’est quoi OpenStack ?
OpenStack représente une plateforme polyvalente conçue pour la création et la gestion de clouds, qu'ils soient destinés à un usage privé ou public. Cette solution met à disposition une série d'outils, appelés "projets", visant à fournir un ensemble complet de services de cloud computing, couvrant des aspects essentiels tels que le calcul, la gestion réseau, le stockage, la gestion des identités et la gestion d'images. Dans le contexte de la virtualisation, OpenStack permet de découpler les ressources matérielles (telles que le stockage, la puissance de calcul, la mémoire, etc.) des diverses applications ou programmes des fournisseurs.
Ce découplage est réalisé grâce à l'utilisation d'un hyperviseur, puis ces ressources virtualisées sont allouées dynamiquement en fonction des besoins spécifiques. OpenStack s'appuie sur des interfaces de programmation d'application (API) pour étendre la virtualisation à son maximum, en organisant ces ressources virtuelles en pools distincts. Ces pools sont associés à des outils de cloud computing standard, ce qui permet aux administrateurs et aux utilisateurs d'interagir directement avec eux pour l'administration et l'utilisation des ressources.
En fin de compte, OpenStack se positionne comme un moyen puissant pour déployer des infrastructures de type IaaS (Infrastructure as a Service), offrant ainsi flexibilité et contrôle dans la gestion de ressources virtuelles, que ce soit dans un environnement privé ou public.
II-2 OpenStack n’est pas une plateforme de gestion de virtualisation
OpenStack et les plateformes de gestion de la virtualisation partagent des similitudes dans leur capacité à surveiller les ressources virtualisées, à identifier ces ressources, à générer des rapports, et à automatiser des processus au sein d'environnements diversifiés faisant appel à différents fournisseurs.
Cependant, la différence majeure réside dans le fait qu'OpenStack va plus loin que les plateformes de gestion de la virtualisation. En effet, OpenStack utilise effectivement ces ressources pour mettre en place et exécuter des outils. Ces outils créent un environnement cloud qui répond pleinement aux cinq caractéristiques du Cloud Computing définies par le NIST (National Institute of Standards and Technology) : un réseau, des ressources en pools, une interface utilisateur, des capacités d'approvisionnement, et une allocation/automatisation du contrôle des ressources.
Un pool de ressources, également appelé ressource pool, représente une structure logique qui offre une gestion souple des ressources. Ces pools de ressources peuvent être organisés en hiérarchies pour permettre une partition logique des ressources CPU et mémoire disponibles, offrant ainsi une flexibilité dans l'allocation de ces ressources.
II-3 Fonctionnement de OpenStack.
OpenStack est un ensemble de commandes que l'on appelle scripts. Ces scripts sont regroupés
dans des paquets appelés projets qui transmettent les tâches nécessaires à la création
d'environnements cloud. OpenStack s'appuie sur deux types de logiciels pour créer ces environnements :
- un logiciel de virtualisation qui crée une couche de ressources virtuelles à partir du matériel ;
- un système d'exploitation de base qui exécute les commandes transmises par les scripts OpenStack.
Le principe est le suivant : OpenStack ne virtualise pas les ressources, mais utilise ces dernières pour construire des clouds. OpenStack n'exécute pas non plus de commandes, mais les transmet au système d'exploitation de base. Les trois technologies, c'est-à-dire OpenStack, le logiciel de virtualisation et le système d'exploitation de base, doivent fonctionner parfaitement ensemble. Cette interdépendance explique pourquoi tant de clouds OpenStack sont déployés avec Linux.
II-4 Les composants de OpenStack.
OpenStack est composé d'une série de logiciels et de projets au code source libre qui sont maintenus par la communauté incluant: OpenStackCompute (nommé Nova), OpenStack Object Storage (nommé Swift), et OpenStack Image Service (nommé Glance) et des composants complémentaires.
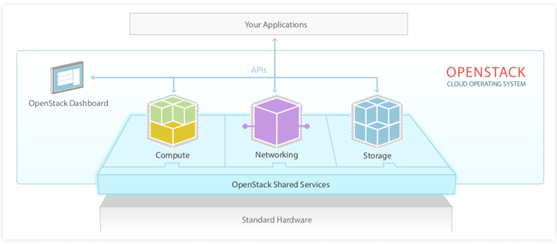
Figure 4:Version simple
a- OpenStackCompute (projet Nova)
Nova est une des briques principales d' OpenStack. Son but est de gérer les ressources de calcul des infrastructures. Pour cela, Nova contrôle les hyperviseurs par l'intermédiaire de la libvirt ou directement par les API de certains hyperviseurs. Aujourd'hui l'hyperviseur le mieux supporté reste KVM, mais Nova fonctionne aussi avec Xen, ESX, et Hyper-V voire avec des gestionnaires de conteneur comme Docker et plus récemment l'hyperviseur LXD de Canonical. L'architecture de la brique de Nova est conçue pour évoluer horizontalement en rajoutant du matériel. D'ailleurs Nova fonctionne avec du matériel non spécialisé ce qui permet de réutiliser des serveurs existants par exemple.
b- OpenStack Object Storage (projet Swift)
Le stockage objet d’ OpenStack s'appelle Swift. C'est un système de stockage de données redondant et évolutif. Les fichiers sont écrits sur de multiples disques durs répartis sur plusieurs serveurs dans un Data-center. Il s'assure de la réplication et de l'intégrité des données au sein du cluster. Le cluster (grape de serveurs sur un réseau, appelé ferme ou grille de calcul) Swift évolue horizontalement en rajoutant simplement de nouveaux serveurs. Si la logique de Swift est applicative, elle permet l'utilisation de matériel peu coûteux et non spécialisé.
En août 2009, c'est Rackspace qui a commencé le développement de Swift, en remplacement de leur ancien produit nommé Cloud Files. Aujourd'hui c'est la société SwiftStack qui mène le développement de Swift avec la communauté.
Architecture de Swift :
Swift est compose de trois types d’objets différents :
- Swift-Account : Gère une base de données Sqlite3 contenant les objets de stockage.
- Swift-Container : Gère une autre base données sqlite3 contenant la topologie des serveurs.
- Swift-Object : Topologies des objets réel enregistrées sur chaque nœud.
c- OpenStack Image Service (projet Glance)
Le service d'image d' OpenStack s'appelle Glance. Il permet la découverte, l'envoi et la
distribution d'image disque vers les instances. Les images stockées font office de modèle de
disque. Le service Glance permet aussi de stocker des sauvegardes de ces disques. Glance peut stocker ces images disques de plusieurs façons : dans un dossier sur serveur, mais aussi à travers le service de stockage objet d’ OpenStack ou dans des stockages décentralisés comme Ceph. Glance ne stocke pas seulement des images, mais aussi des informations sur celles-ci, les métadonnées. Ces métadonnées sont par exemple le format du disque (comme QCOW2 ou RAW) ou les conteneurs de celles-ci (OVF par exemple).
L’image suivante montre écosystème d’images d’ OpenStack en se basant sur le projet Nova et Swift :
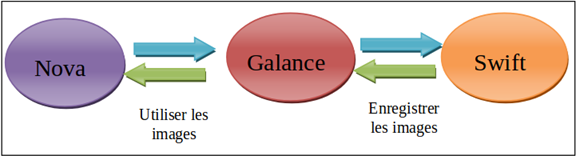
Figure5 : Écosystème d’images d’ OpenStack
d- Stockage bloc : Cinder
Le service de stockage en mode bloc d' OpenStack s'appelle Cinder. Il fournit des périphériques persistants de type bloc aux instances OpenStack. Il gère les opérations de création, d'attachement et de détachement de ces périphériques sur les serveurs. En plus du stockage local sur le serveur, Cinder peut utiliser de multiples plateformes de stockage tel que Ceph, EMC (ScaleIO, VMAX et VNX), GlusterFS, Hitachi Data Systems, IBM Storage (Storwize family, SAN Volume Controller, XIV Storage System, et GPFS), NetApp, HP (StoreVirtual et 3PAR) et bien d'autres.
Le stockage en mode bloc est utilisé pour des scénarios performants comme celui du stockage de base de données, mais aussi pour fournir au serveur un accès bas niveau au périphérique de stockage. Cinder gère aussi la création d'instantanés (snapshots), très utile pour sauvegarder des données contenues dans les périphériques de type bloc. Les instantanés peuvent être restaurés ou utilisés pour créer de nouveaux volumes.
e- Le réseau : Neutron
Le service Neutron d' OpenStack (anciennement Quantum) permet de gérer et manipuler les réseaux et l'adressage IP au sein d' OpenStack. Grâce à Neutron, les utilisateurs peuvent créer leurs propres réseaux, contrôler le trafic à travers des groupes de sécurité (security groups) et connecter leurs instances à un ou plusieurs réseaux. Neutron gère aussi l'adressage IP des instances en leur assignant des adresses IP statiques ou par l'intermédiaire du service DHCP. Il fournit aussi un service d'adresse IP flottante que l'on peut assigner aux instances afin d'assurer une connectivité depuis Internet. Ces adresses IP flottantes peuvent être réassignées à d'autres instances en cas de maintenance ou de défaillance de l'instance originelle. Neutron fournit différents types de déploiement réseau en fonction de l'infrastructure cible.
Les types de réseaux les plus déployés sont les réseaux plats (flat network), les réseaux à VLAN, VXLAN ou à tunnel GRE. Neutron gère ses déploiements grâce à des modules complémentaires qui lui permettent de communiquer avec des équipements ou logiciels de gestions réseau. Les plug-ins les plus utilisés sont OpenVswitch, ML2, LinuxBridge, mais aussi Cisco Nexus, Juniper OpenContrail et d'autres.
Dans son architecture, Neutron a été construit en suivant la philosophie des réseaux de nouvelle génération dite SDN. Bien qu'il ne le gère pas lui-même, certains modules tirent parti des fonctionnalités SDN des équipements qu'ils contrôlent. Lors de son utilisation avec OpenVswitch par exemple, Neutron utilise une combinaison de règles Iptables et OpenFlow pour gérer le trafic vers les instances.
f- Tableau de bord : Horizon
OpenStack fournit un tableau de bord qui s'appelle Horizon. Il s'agit d'une application web qui
permet aux utilisateurs et aux administrateurs de gérer leurs clouds à travers une interface graphique. Comme toutes les briques d' OpenStack cette application est libre et il n'est donc pas rare de voir des versions modifiées par les fournisseurs de cloud Computing ou par d'autres sociétés commerciales ne serait-ce que pour y faire apparaître leur nom et logo, mais aussi pour y intégrer leurs systèmes de métrologie ou de facturation par exemple. Cette application est écrite en python et notamment grâce aux frameworks de développement web tels que Django et elle tire parti des API REST fournies par les autres composants d' OpenStack comme Nova, Cinder ou Neutron.
g- Service d'identité : Keystone
Le service d'identité d' OpenStack s'appelle Keystone. Il fournit un annuaire central contenant
la liste des services et la liste des utilisateurs d' OpenStack ainsi que leurs rôles et autorisations. Au sein d' OpenStack tous les services et tous les utilisateurs utilisent Keystone afin de s'authentifier les uns avec les autres. Keystone peut s'interfacer avec d'autres services d'annuaire comme LDAP. Il supporte plusieurs formats d'authentification comme les mots de passe et autres.
h- Télémétrie : Ceilometer
Le service de télémétrie d' OpenStack s'appelle Ceilometer. Il permet de collecter différentes
métriques sur l'utilisation du cloud. Par exemple il permet de récolter le nombre d'instances lancé dans un projet et depuis combien de temps. Ces métriques peuvent être utilisées pour fournir des informations nécessaires à un système de facturation par exemple. Ces métriques sont aussi utilisées dans les applications ou par d'autres composants d' OpenStack pour définir des actions en fonction de certains seuils comme avec le composant d'orchestration.
i- Orchestration : Heat
Heat est le composant d'orchestration d' OpenStack. Il permet de décrire une infrastructure sous forme de modèles. Dans Heat, ces modèles sont appelés des stacks. Heat consomme ensuite ces modèles pour aller déployer l'infrastructure décrite sur OpenStack. Il peut aussi utiliser les métriques fournies par Ceilometer pour décider de créer des instances supplémentaires en fonction de la charge d'une application par exemple.
j- Service de base de données : Trove
Trove est le service qui permet d'installer et de gérer facilement des instances de base de données relationnelle et NoSQL au sein d' OpenStack. À ce jour les services de base de données supportés sont les suivants : MySQL, Redis, PostgreSQL, Mongodb, Cassandra, Couchbase et Percona.
k- Traitement des données : Sahara
Sahara a pour but de fournir aux utilisateurs les moyens simples de provisionner des clusters
de Hadoop en spécifiant plusieurs paramètres comme la version, la topologie du cluster ou d'autres. Après avoir rempli ces paramètres, Sahara déploie le cluster en quelques minutes. Sahara fournit aussi les moyens d'évolution du cluster en rajoutant des nœuds à la demande.
Les autres services sont :
-Ironinc (service de Bare Metal provisionning)
-Manila: service de gestion des systèmes de fichier partagés.
-Zaqar: service de middleware à la demande.
-Designate : service de gestion des DNS.
-Barbican: service de gestion des clés et secrets.
-Magnum: service de gestion des conteneurs.
Schéma des interactions entre les différents composants d’ OpenStack :
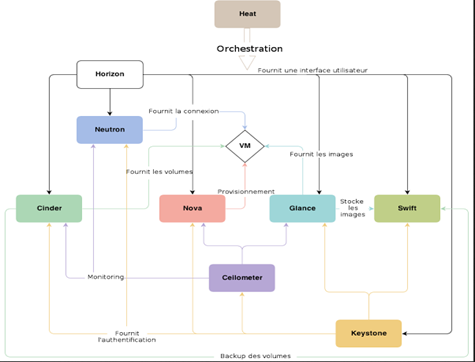
Figure7 : Interactions entre les différents projets OpenStack
L’architecture d’ OpenStack peut aussi être vue sous forme de nœuds :
-Contrôleur : Le nœud contrôleur héberge le service d’Identité, le service d’Image, la partie management du Compute et du Réseau, plusieurs agents Réseau, et le Dashboard. Il inclut également les services support comme une base de données SQL, la file de message, et NTP.
En option, le nœud contrôleur peut faire tourner des parties de services de Stockage par Blocs, de Stockage Objet, d’Orchestration et de Télémétrie.
Le nœud contrôleur nécessite au minimum deux interfaces réseau.
-Compute : Le nœud compute exécute la partie hyperviseur de Compute qui fait fonctionner les instances. par défaut, Compute utilise l’hyperviseur KVM. Le nœud compute héberge également un agent du service Réseau qui connecte les instances aux réseaux virtuels et fournit des services de firewall aux instances via les groupes de sécurité.
Vous pouvez déployer plus d’un nœud compute. Chaque nœud nécessite au minimum deux interfaces réseau.
- Stockage par bloc : Le nœud optionnel de Stockage par Blocs contient les disques que les services de Stockage par Blocs et de Systèmes de Fichiers Partagés provisionne pour les instances.
Pour simplifier, le trafic du service entre les nœuds compute et ce nœud utilise le réseau de management. Les environnements de production devraient implémenter un réseau de stockage séparé pour accroître la performance et la sécurité.
-Stockage par objets : Le nœud optionnel de Stockage Objet contient les disques que le service de Stockage Objet utilise pour stocker les comptes, les conteneurs et les objets.
Pour simplifier, le trafic du service entre les nœuds compute et ce nœud utilise le réseau de management. Les environnements de production devraient implémenter un réseau de stockage séparé pour accroître la performance et la sécurité.
II-5 Avantages et limites d’ OpenStack
a- Avantages
-Open Source: L’ un des avantage d’ OpenStack, c’est qu’il s’agit d’un projet open source. La technologie est disponible librement, et non pas via un autre fournisseur.
-Modèles: Un autre grand avantage qu’offre OpenStack, ce sont les modèles. Pour chaque action que vous effectuez, vous pouvez en effet utiliser des modèles. Autrefois, vous deviez configurer un serveur virtuel, ce qui pouvait facilement prendre une journée (un peu comme lorsque vous achetez un nouvel ordinateur portable). Un tel nouveau serveur nécessite en effet un système d’exploitation, mais vous ne pouvez pas commencer à l’utiliser avant que tous les services nécessaires pour prendre en charge votre application soient configurés, comme p. ex. les serveurs web, les serveurs de base de données, etc. Le grand avantage, c’est que via OpenStack, vous pouvez déterminer la mise en page d’un serveur dans un tel modèle et laisser le serveur virtuel s’installer automatiquement selon ce modèle. Cela permet donc de faciliter et d’accélérer l’entièreté du processus.
-L’outillage : On retrouve nombre d’outils pour automatiser tâches et opérations.
-Infrastructure de capacité supérieure, capable de gérer des exigences élevées en matière de calcul et de stockage ;
- Allocation efficace des ressources en fonction des besoins de l’utilisateur ;
b- Inconvénients
- Coûts de formation/ montée en puissance
- Matériels dédiées en fonction du rôles du serveur.
-Il est difficile à configurer et à déployer : puisque OpenStack est déployé dans le cadre de projets spécifiques d’incubateurs, l'expertise et le temps sont nécessaires pour l'ouvrir ;
- Il est assez difficile à installer et fonctionnerait mieux avec des équipements DELL.
III- CAS PRATIQUE : Mise sur pied d’un cloud privée a l’aide d’ OpenStack.
Dans ce chapitre, nous allons mettre en place notre solution OpenStack en montrant le dimensionnement des couches matérielles, notamment des serveurs et enfin nous allons présenter des spécifications sur les autres éléments à installer avant d'installer la solution proprement dite.
III-1 Architecture d’installation
Selon la documentation OpenStack il y a plusieurs architectures possibles. La figure suivante montre ces derniers.

Figure 8: Les différents architectures possibles
Pour nos premiers pas nous avons donc essayé la première installation sur un seul nœud dans laquelle tous les services ainsi que toutes les instances sont hébergés au sein du même serveur. Cette solution nous permet uniquement d’effectuer des tests sur le Cloud pour des fins purement techniques.
III-2 Utilisateurs du système
a- L’administrateur
L'administrateur est toute personne physique ayant reçu les droits d'administration. Généralement, lors de l'installation, on configure les droits du premier administrateur.
Un administrateur peut :
-Ajouter de nouveaux administrateurs
-Supprimer des administrateurs
-Ajouter de nouveaux utilisateurs
-Créer un projet.
-Créer de nouvelles machines virtuelles
-Gérer et créer un réseau
Chaque utilisateur possède un login et un mot de passe unique, modifiable à volonté par le concerné.
b- L’utilisateur
L'utilisateur est toute personne physique de l'entreprise ayant reçu un compte d'accès.
A ce titre, il peut :
- Stocker des données dans la limite de ses possibilités
- Instancier des machines virtuelles.
III-3 Installation de OpenStack
Comme c’est une solution libre, donc son installation a été conduite sous Ubuntu LTS server 16.04 64 bits. L'installation de ce système d'exploitation se fait sur une machine virtuelle, afin d'optimiser les ressources de la machine. Le logiciel de virtualisation utilisé est VirtualBox.
III-3-1 Installation et Configuration de VritualBox
Pour installer VirtualBox il faut vérifier que le PC hôte supporte la virtualisation (VT-X doit être activé dans le BIOS), après l’installation on doit configurer le réseau de VirtualBox avec les deux interfaces réseaux suivantes :
Eth0 : Bridge Pour la gestion d’ OpenStack.
Eth1 : Bridge Pour l’accès vers l’internet
III-3-2 Création de la machine virtuelle
Nous avons dû créer une machine avec les paramètres suivants :
-Nom : Ubuntu 16.04 – OpenStack Grizzly.
-Type de système d’exploitation : Linux.
-Version : Ubuntu 16.04 LTS Server 64bits.
-Mémoire (RAM) : 1.400 GB.
-2 disques : 30 GB pour les systèmes + 30 GB pour le composant Cinder.
-Processeur (facultatif mais conseillé) : 1
III-3-3 Étape d’installation d’ OpenStack
Après avoir installé Ubuntu LTS server 16.04 sur une machine virtuelle considérée comme notre serveur, il va falloir installer OpenStack.
Il existe plusieurs méthodes pour l’installer, dont :
-DevStack.
-installation via des scripts.
-Depuis les packages
Lors de notre déploiement nous avons choisi une installation depuis les packages.
a- Configuration des cartes réseaux
Après avoir disposé d’une connexion internet activée et configurée, on modifie avec
les droits d’administrateur le fichier (etc/network/interfaces).
b- Préparation de la machine virtuelle en ajoutant les dépôts d’installation d’ OpenStack
C’est-à-dire télécharger les package nécessaire pour installer OpenStack
c- Mettre à jour le système
Faire une mise à jour du système d’exploitation, en l’occurrence Ubuntu.
d- Installation de MySQL et RabbitMQ
Installation de la base de données MySQL.
e- Installation de Keystone
Le composant Keystone est chargé de la gestion des utilisateurs et des services:
apt-get install keystone
f-Installation de Glance
Ce service est chargé de distribuer les images de disque dur système utilisées par les machines virtuelles.
apt-get install glance
g- Installation de KVM
apt-get install kvm libvirt-bin pm-utils
h- Installation de Nova
Permet la gestion des machines virtuelles.
j- Installation de Cinder
Commande beaucoup trop longue
k- Installation d’Horizon
Dashboard Horizon permet de simplifier l'administration du serveur et des projets. L'accès se fait à partir d'un navigateur web pointant à l'adresse du serveur. Les différents services doivent être installés et configurés avant de pouvoir les utiliser. Une grande partie des commandes est alors à portée d'un clic de souris.
apt-get install openstack-dashboard memcached
Pour accéder a l’installation d’administration : http://ip_address/horizon
cet interface offre la possibilité a l’utilisateur de crée :
- Des projets, configurées et les gérées
- Un nouvelle utilisateur
- Un réseau
- Crée un sous-réseau
- Des routeurs virtuelle
Tous ces notions seront vu en tp.
Conclusion
Au cours de ce cours, nous avons approfondi notre compréhension du Cloud Computing et exploré la mise en place d'une solution open source pour les besoins d'une entreprise. Nous avons commencé par établir les bases essentielles, notamment en définissant les concepts fondamentaux du Cloud, son architecture, ainsi que les différents types de Cloud (privé, public, hybride) et les services proposés (IaaS, PaaS, SaaS).
Ensuite, nous avons entrepris une analyse comparative des différentes solutions open source disponibles pour la création d'un Cloud privé. Cette démarche nous a permis de prendre des décisions éclairées en choisissant la solution la mieux adaptée à nos besoins spécifiques.
Nous avons ensuite mis en œuvre la solution Cloud que nous avons retenue, en l'occurrence, OpenStack. Cette mise en place a impliqué la préparation d'un environnement propice. Par la suite, nous avons procédé à l'installation et à la configuration d'OpenStack.
Il est à noter que l'ensemble de ces opérations s'est déroulé sur un système d'exploitation Ubuntu 16.04 Server, hébergé dans une machine virtuelle gérée par VirtualBox. Ce processus nous a permis de créer une infrastructure Cloud personnalisée pour l'entreprise, ouvrant ainsi la voie à des possibilités flexibles et évolutives pour répondre à ses besoins informatiques.
Bibliographie
- Étude_et_mise_en_place_d’une_solution_CloudComputing_privée_pour _une_entreprise.pdf
- OpenStack : http://www.OpenStack.html
- supinfo: http://www.supinfo.com/articles/single/2955-initiation-openStack
- OpenStack.fr.pdf

? Salut, moi c’est PandaCodeur !
Un jour, j’ai oublié un point-virgule…
et toute ma forêt a planté ?
Mais grâce à Pandacodeur, j’ai appris de mes erreurs !
? Sur Pandacodeur, tu peux :
✔ apprendre la programmation de façon pratique
✔ t’entraîner avec des quiz interactifs
✔ comprendre grâce à des exercices corrigés
✔ te préparer efficacement à l’examen
Prêt à coder sans paniquer ? ?
Questions / Réponses
Ajouter un commentaire