CloudStack
Introduction
Avec l'évolution constante des systèmes informatiques, la demande en espace de stockage, en simplicité d'utilisation et en flexibilité a considérablement augmenté. Le cloud computing se présente comme une réponse à ce défi croissant. En substance, le cloud computing offre des services informatiques à la demande, accessibles de n'importe où et à tout moment, pour n'importe qui. Cette technologie permet aux entreprises et aux particuliers d'externaliser le stockage de leurs données, d'accéder à une puissance de calcul supplémentaire pour le traitement de grandes quantités d'informations, et de profiter de services à la demande.
Cependant, pour créer des services cloud, il est essentiel de disposer des outils appropriés, notamment des logiciels permettant de déployer et de gérer ces services. C'est là qu'intervient CloudStack, un logiciel open-source conçu pour la création, la gestion et le déploiement de services cloud d'infrastructure. Notre travail se concentrera principalement sur la mise en œuvre d'une solution cloud à l'aide de CloudStack.
Pour ce faire, nous commencerons par explorer les concepts fondamentaux du cloud computing. Ensuite, nous nous pencherons sur la présentation, l'installation et la configuration de CloudStack. Enfin, nous mettrons en œuvre concrètement notre propre solution CloudStack. Ce processus nous permettra de tirer parti de la puissance du cloud computing pour répondre aux besoins croissants en matière de stockage et de traitement des données de manière efficace et flexible.
Partie 1:
Le Cloud Computing
L’expression Cloud computing vient des premiers temps de l’Internet où l’habitude était prise de dessiner le réseau comme un nuage.
Et Kevin Marks de Google dira à ce sujet que:
“We didn’t care where the messages went… the cloud hid it from us”.
Le premier cloud (nuage) était construit autour du réseau (abstraction TCP/IP). Le deuxième cloud était celui des documents (abstraction du World Wide Web). Le nuage actuel, Cloud computing, est une abstraction de l’infrastructure informatique qui masque la complexité des serveurs, des applications, des données et des plates-formes hétérogènes.
Le cloud computing est une technologie qui consiste en une interconnexion et une coopération de ressources informatiques, situées dans diverses structures internes, externes ou mixtes et dont le mode d'accès est basé sur les protocoles et standards de l’internet. En d’autres mots, le Cloud Computing est un modèle Informatique qui permet un accès facile et à la demande par le réseau à un ensemble partagé de ressources informatiques configurables (serveurs, stockage, applications et services) qui peuvent être rapidement provisionnées et libérées par un minimum d’efforts de gestion ou d’interaction avec le fournisseur du service. L'idée principale à retenir est que le Cloud n'est pas un ensemble de technologies, mais un modèle de fourniture, de gestion et de consommation de services et de ressources informatiques.
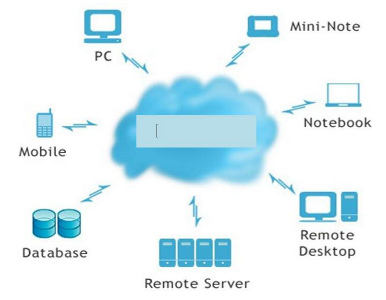
fig1. Représentation du cloud
Le cloud computing est caractériser par plusieurs éléments, on distingue ainsi:
- La virtualisation: elle consiste à faire fonctionner un ou plusieurs systèmes d'exploitation sur un ou plusieurs ordinateurs.
- Le DataCenter: Un centre de traitement de données (data centre en anglais)est un site physique sur lequel se trouvent regroupés des équipements constituants du système d'information de l'entreprise (mainframes, serveurs, baies de stockage, équipements réseaux et de télécommunications, etc.). Il peut être interne et/ou externe à l'entreprise, exploité ou non avec le soutien de prestataires. Il comprend en général un contrôle sur l'environnement (climatisation, système de prévention contre l'incendie, etc.), une alimentation d'urgence et redondante, ainsi qu'une sécurité physique élevée.

Fig2: image d’un datacenter (Legrand datacenter en occurrence).
- Une Plateforme collaborative: Une plate-forme de travail collaboratif est un espace de travail virtuel. C'est un site qui centralise tous les outils liés à la conduite d'un projet et les met à disposition des acteurs. L'objectif du travail collaboratif est de faciliter et d'optimiser la communication entre les individus dans le cadre du travail ou d'une tâche.
L’on parle généralement de 3 services qu’on utilise différemment selon les besoins. Certains appellent ces services les couches de clouds et ils sont souvent représentes sous forme d’une pyramide comme la montre la figure suivante.
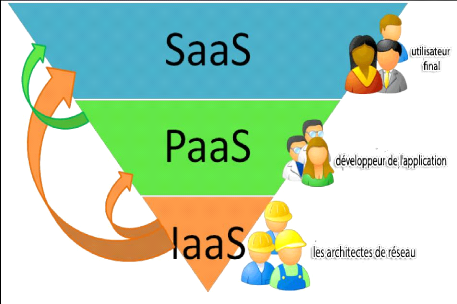
Fig3: couches du cloud
IaaS : Infrastructure as a service, c’est la couche inférieure qui représente les ressources matérielles (puissance de calcul, espace de stockages, serveur ….). Les clients, à ce niveau n’ont pas de contrôle sur ces ressources mais plutôt sur les systèmes d’exploitation et les applications qu’ils peuvent installer sur le matériel alloué.
PaaS : Plateforme as a Service, c’est la couche intermédiaire où le fournisseur contrôle le système d’exploitation et les outils d’infrastructure et par suite les clients n’ont le contrôle que sur les applications déployées.
SaaS : Software as a service, c’est la couche supérieure qui correspond à la mise à disposition des applications comme étant des services accessibles via internet. Les clients n’ont plus besoin donc à installer les applications sur ses postes.
Nous distinguons quatre modèles de déploiement qui n’ont pas une grande influence sur les systèmes déployés.
- Cloud public : C’est le cloud dans le sens traditionnel où les services sont offerts au grand public et peuvent être payants ou même gratuit. Les ressources dynamiquement provisionnées peuvent être accessibles par internet ou bien par un fournisseur.
- Cloud privé : Ce cloud est destiné entièrement à un organisme et peut être déployé sous deux formes déférentes :
- Cloud privé interne : Hébergé et géré par l’entreprise
- Cloud privé externe : Hébergé et géré par un tiers et accessible via des réseaux de type VPN.
- Cloud hybride : C’est la combinaison du cloud public et cloud privé par une entreprise.
- Cloud communautaire : Un ensemble d’organisations qui ont un intérêt commun partagent l’infrastructure du cloud. Il est plus coûteux que le cloud public mais offre d’autres avantages.
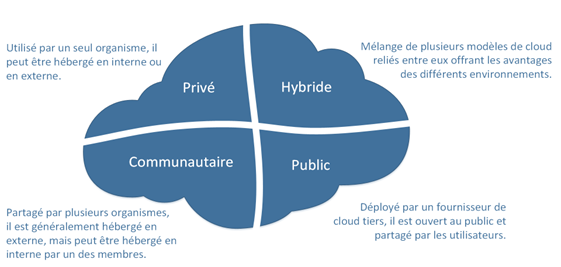
Fig4: modèles de déploiement de cloud
Pour augmenter la fiabilité du cloud, vous pouvez éventuellement regrouper des ressources dans plusieurs régions géographiques. Une région est la plus grande unité d'organisation disponible dans un déploiement d’une solution cloud. Une région est composée de plusieurs zones de disponibilité, où chaque zone est à peu près équivalente à un centre de données. Chaque région est contrôlée par son propre cluster de serveurs de gestion, s'exécutant dans l'une des zones. Les zones d'une région sont généralement situées à proximité géographique. Les régions sont une technique utile pour la tolérance aux pannes et la reprise après sinistre.
En regroupant les zones en régions, le cloud peut atteindre une disponibilité et une évolutivité accrues. Les comptes d'utilisateurs peuvent s'étendre sur plusieurs régions, ce qui permet aux utilisateurs de déployer des ordinateurs virtuels dans plusieurs régions très dispersées. Même si l'une des régions devient indisponible, les services restent disponibles pour l'utilisateur final via des ordinateurs virtuels déployés dans une autre région. Et en regroupant les communautés de zones sous leurs propres serveurs de gestion proches, la latence des communications dans le cloud est réduite par rapport à la gestion de zones dispersées à partir d'un seul serveur de gestion central.
Les enregistrements d'utilisation peuvent également être consolidés et suivis au niveau de la région, créant des rapports ou des factures pour chaque région géographique.
Une zone est la deuxième plus grande unité d'organisation au sein d'un déploiement d’une solution cloud. Une zone correspond généralement à un seul centre de données, bien qu'il soit possible d'avoir plusieurs zones dans un centre de données. L’organisation des infrastructures en zones présente l’avantage de fournir une isolation physique et une redondance. Par exemple, chaque zone peut avoir sa propre alimentation en énergie et sa propre liaison montante, et les zones peuvent être largement séparées géographiquement (bien que cela ne soit pas requis).
Une zone est composée de:
- Un ou plusieurs pods. Chaque pod contient un ou plusieurs clusters d'hôtes et un ou plusieurs serveurs de stockage principaux.
- Une zone peut contenir un ou plusieurs serveurs de stockage principaux, partagés par tous les pods de la zone.
- Stockage secondaire, partagé par tous les pods de la zone.
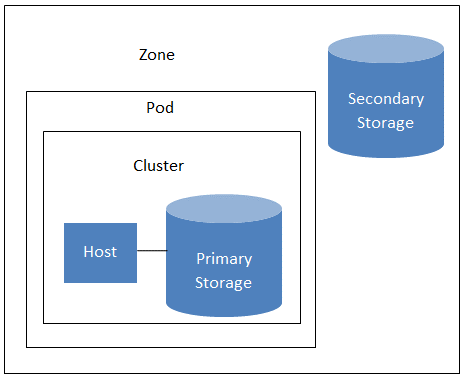
Fig 5: architecture de déploiement d'une infrastructure cloud
Un pod représente souvent un seul rack(tiroir destine a recevoir des disques durs ) ou une rangée de racks. Les hôtes dans le même pod sont dans le même sous-réseau. Un pod est la deuxième plus grande unité d'organisation au sein d'un déploiement de solution cloud. Les pods sont contenus dans des zones. Chaque zone peut contenir un ou plusieurs pods. Un pod est constitué d'un ou plusieurs clusters d'hôtes et d'un ou plusieurs serveurs de stockage principaux. Les pods ne sont pas visibles pour l'utilisateur final.
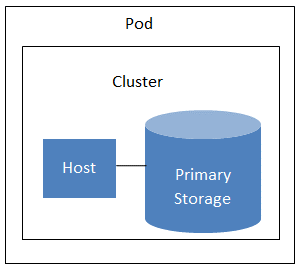 Fig 6 achitecture d'un POD
Fig 6 achitecture d'un POD
Un cluster est composé d'un ou plusieurs hôtes et d'une ou plusieurs ressources de stockage principales. Les hôtes d'un cluster doivent tous avoir un matériel identique, exécuter le même hyperviseur, se trouver sur le même sous-réseau et accéder au même stockage principal partagé. Les instances de machine virtuelle (VM) peuvent être migrées en direct d'un hôte à un autre au sein du même cluster, sans interrompre le service fourni à l'utilisateur.
Un hôte est un seul ordinateur physique. Les hôtes fournissent les ressources informatiques qui exécutent les ordinateurs invités.
Le stockage principal est associé à un cluster et / ou une zone. Il stocke les volumes de disque de tous les ordinateurs virtuels exécutés sur des hôtes de ce cluster. Vous pouvez ajouter plusieurs serveurs de stockage principaux à un cluster ou à une zone (au moins un est requis au niveau du cluster). Le stockage principal est généralement situé à proximité des hôtes pour améliorer les performances. Le stockage principal peut être statique ou dynamique.
Le stockage secondaire stocke les éléments suivants:
- Modèles: images de système d'exploitation pouvant être utilisées pour démarrer des ordinateurs virtuels et pouvant inclure des informations de configuration supplémentaires, telles que des applications installées
- Images ISO - images de disque contenant des données ou un support amorçable pour les systèmes d'exploitation
- Instantanés de volume de disque - Copies enregistrées de données de machine virtuelle pouvant être utilisées pour la récupération de données ou pour créer de nouveaux modèles.
Les éléments de la mémoire secondaire sont disponibles pour tous les hôtes compris dans la portée de la mémoire secondaire, qui peut être définie par zone ou par région.
Un ou plusieurs réseaux physiques peuvent être associés à chaque zone. Le réseau physique correspond généralement à une carte réseau physique sur l'hôte. Chaque réseau physique peut transporter un ou plusieurs types de trafic réseau. Les choix de type de trafic pour chaque réseau varient en fonction de vos choix de réseau.
Un réseau physique est le matériel réseau réel et le câblage dans une zone. Une zone peut avoir plusieurs réseaux physiques.
Il existe deux catégories de solution Cloud Computing privé, les solutions propriétaires et les solutions libres et gratuites.
Depuis quelques années, les éditeurs de logiciel se sont lancés dans la technologie Cloud. Il existe à ce jour une multitude d'offre de logiciel pour installer son propre Cloud privé. Ainsi nous avons: Office 365, VmWare qui sont les plus connus.
Comme dans tous les domaines de l'informatique de nos jours, le Cloud Computing n'échappe pas à la règle du logiciel libre. Face à des solutions payantes et propriétaires, il existe des solutions libres et gratuites.
Ces logiciels sont développés en communauté, et font l'objet de mises à jour régulières. Ils peuvent être modifiés à volonté suivant l'utilisation que l'on veut en faire. Voici une liste non exhaustive de quelques logiciels libres pour créer son Cloud privé.
- OpenStack: c’est un logiciel libre qui permet la construction de Cloud privé et public. OpenStack est aussi une communauté et un projet en plus d'un logiciel qui a pour but d'aider les organisations à mettre en œuvre un système de serveur et de stockage virtuel. OpenStack est composé d'une série de logiciels et de projets au code source libre qui sont maintenu par la communauté incluant: OpenStack Compute(nommé Nova), OpenStack Object Storage (nommé Swift), et OpenStack Image Service (nommé Glance). Il s'installe sur un système d'exploitation libre comme Ubuntu ou Debian et se configure entièrement en ligne de commande. C'est un système robuste et qui a fait ses preuves auprès des professionnels du domaine. Son principal inconvénient est qu'il est assez difficile à installer et fonctionnerait mieux avec des équipements DELL. Il est bien vrai que de petits utilitaires ont été développé pour améliorer l'installation, comme par exemple Crowbar, il reste néanmoins assez fastidieux. OpenStack reste un bon logiciel si notre couche matérielle est composée d'équipements DELL ce qui est aussi un des ses défauts majeurs.
- OwnCloud: c’est un logiciel libre qui vous permet de créer votre propre Cloud prive c'est à dire, accéder à vos données n'importe où, à partir d'un simple navigateur ou de différents systèmes d'exploitation grâce à des applications dédiées et, plus intéressant, de les synchroniser. L'intérêt principal OwnCloud est que l'on reste propriétaire de nos données. OwnCloud propose une solution que n'importe qui peut installer sur son propre serveur. Ainsi, la solution s'adresse aux particuliers comme aux entreprises, même si ces dernières peuvent bénéficier de fonctions supplémentaires dans la version qui leur est dédiée.
- CloudStack est un logiciel libre de la fondation apache. Il permet de créer des Cloud Computing privés et publics. Malgré sa sortie récente, il jouit d'une popularité chez les professionnels du secteur. L'avantage de ce logiciel c'est qu’il peut être facilement intégrer a une architecture déjà existante. Il est compatible avec les différentes couches matérielles. C’est donc sur ce dernier que sera consacré la seconde partie de ce document.
Partie 2:
CloudStack
Apache CloudStack est une plate-forme Open-Source qui gère et orchestre des pools de ressources de stockage, de réseau et d'ordinateurs pour créer un nuage de calcul IaaS public ou privé.
Avec CloudStack, vous pouvez:
- Configurez un service de cloud computing élastique à la demande.
- Autoriser les utilisateurs finaux à mettre en service des ressources.
CloudStack est originellement développé par cloud.com anciennement connu sous le nom VMOps. Il est mis a disposition du public en 2010 sous licence GNU. Plus tard le logiciel est confie a un des associes de cloud.com a savoir citrix qui en publie la version 3.0 en février 2012. En avril de la même année, citrix cède le logiciel a Apache Software Foundation(ASF). Ce dernier livre ainsi la toute première version stable du logiciel a savoir la 4.0.2. A l’heure de la rédaction de ce document la dernière version est 4.13.0.0.
CloudStack fonctionne avec une variété d'hyperviseurs et de technologies similaires à celles d'un hyperviseur. Un seul cloud peut contenir plusieurs implémentations d'hyperviseur.À partir de la version actuelle, CloudStack prend en charge:
- vSphere via(vCenter)
- KVM
- Xenserver
- LXC
- BareMetal (via MPI)
CloudStack peut gérer des dizaines de milliers de serveurs physiques installés dans des centres de données répartis géographiquement. Le serveur de gestion évolue de manière quasi linéaire, éliminant ainsi le besoin de serveurs de gestion au niveau du cluster. La maintenance ou d'autres pannes du serveur de gestion peuvent survenir sans affecter les machines virtuelles exécutées dans le cloud.
CloudStack configure automatiquement les paramètres de réseau et de stockage pour chaque déploiement de machine virtuelle. En interne, un pool de dispositifs virtuels prend en charge l’opération de configuration du cloud proprement dit. Ces appareils offrent des services tels que pare-feu, routage, DHCP, VPN, proxy de console, accès au stockage et réplication du stockage. L'utilisation étendue de machines virtuelles à évolutivité horizontale simplifie l'installation et le fonctionnement continu d'un cloud.
CloudStack propose une interface Web pour administrateurs utilisée pour le provisionnement et la gestion du cloud, ainsi qu'une interface Web pour l'utilisateur final, utilisée pour l'exécution de machines virtuelles et la gestion de modèles de machines virtuelles. L'interface utilisateur peut être personnalisée pour refléter l'apparence du fournisseur de services ou de l'entreprise.
CloudStack fournit une API de type REST pour l'exploitation, la gestion et l'utilisation du cloud.
CloudStack fournit une couche de traduction de l'API EC2 permettant aux outils EC2 courants d'être utilisés dans l'utilisation d'un cloud CloudStack.
CloudStack dispose de plusieurs fonctionnalités pour augmenter la disponibilité du système. Le serveur de gestion lui-même peut être déployé dans une installation à plusieurs nœuds où la charge des serveurs est équilibrée. MySQL peut être configuré pour utiliser la réplication afin de permettre le basculement en cas de perte de la base de données. Pour les hôtes, CloudStack prend en charge la liaison de cartes réseau et l’utilisation de réseaux distincts pour le stockage, ainsi que le multipath iSCSI.
De manière générale, la plupart des déploiements CloudStack comprennent le serveur de gestion et les ressources à gérer. Pendant le déploiement, vous indiquez au serveur de gestion les ressources à gérer, telles que les blocs d'adresses IP, les périphériques de stockage, les hyperviseurs et les VLAN.
L'installation minimale comprend une machine exécutant CloudStack Management Server et une autre machine servant d'infrastructure cloud (dans ce cas, une infrastructure très simple composée d'un hôte exécutant le logiciel d'hyperviseur). Dans son plus petit déploiement, un seul ordinateur peut faire office de serveur de gestion et d'hôte d'hyperviseur.
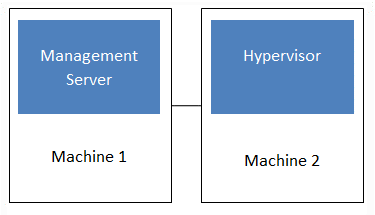
Une installation plus complète consiste en une installation de serveur hautement disponible de gestion multi-nœuds et de plusieurs dizaines de milliers d'hôtes utilisant l'une ou l'autre des technologies de mise en réseau.
CloudStack étant par définition créer pour la gestion des clouds d’infrastructures, il se compose donc des éléments donc des éléments permettant de mettre en œuvre ces infrastructures comme vue dans la partie 1. Ainsi on a:
- Les régions: C’est la plus grande unités d’organisations au sein d’un déploiement CloudStack. Sa définition et sont rôle sont analogue a ceux de la partie 1
- Les Zones: idem pour la zone
- Les Pods
- Les Clusters
- Les Hôtes
- Le Stockage principal
- Le Stockage secondaire
- Le réseau physique
L'architecture utilisée dans un déploiement varie en fonction de la taille et du but de ce dernier. Cette section contient des exemples d’architecture, y compris un déploiement à petite échelle utile pour les tests et les essais et une configuration à grande échelle entièrement redondante pour les déploiements de production ou en entreprise.
Nous illustrerons ici l’architecture d’un réseau d’un déploiement CloudStack à petite échelle. Ce modèle de déploiement peut être installé sur un seul serveur physique comme sur plusieurs. Dans ce système :
- Un pare-feu fournit une connexion à Internet. Le pare-feu est configuré en mode NAT. Il transmet les requêtes HTTP et les appels API depuis Internet au serveur de gestion. Le serveur de gestion réside sur le réseau de gestion.
- Un commutateur couche-2 connecte tous les serveurs physiques et le stockage.
- Un serveur NFS unique fonctionne comme stockage principal et secondaire.
- Le serveur de gestion est connecté au réseau de gestion.
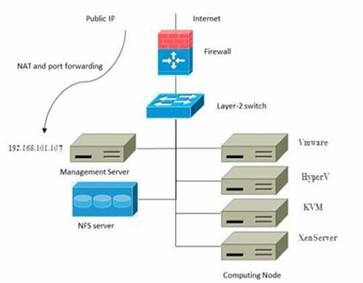
Fig6: modèle de déploiement a petite échelle de CloudStack
Nous illustrerons ici l’architecture d’un réseau de déploiement CloudStack à grande échelle. Dans ce système :
- Une couche de commutation (couche 3) est au cœur du centre de données. Un protocole de redondance de routeur comme VRRP devrait être déployé. Les commutateurs de base généralement haut de gamme incluent également des modules pare-feu. Des appareils pare-feu séparés peuvent également être utilisés si le commutateur couche 3 n'a pas de fonctionnalités de pare-feu intégrées. Ils sont configurés en mode NAT et ils fournissent les fonctions suivantes :
- Transmet les requêtes HTTP et les appels API depuis Internet vers le serveur de gestion.
- Lorsque le nuage s'étend sur plusieurs zones, les pare-feu doivent permettre le VPN de site à site afin que les serveurs dans différentes zones puissent se joindre directement.
- Une couche de commutateur d'accès couche-2 est établie pour chaque module. Plusieurs commutateurs peuvent être empilés pour augmenter le nombre de ports. Dans les deux cas, des paires redondantes de commutateurs de couche 2 doivent être déployées.
- Le cluster du serveur de gestion (y compris les équilibreurs de charge, les nœuds du serveur de gestion et la base de données MySQL) est connecté au réseau de gestion via une paire d'équilibreurs de charge.
- Les serveurs de stockage secondaires sont connectés au réseau de gestion.
- Chaque module contient des serveurs de stockage et de calcul. Chaque serveur de stockage
- et de calcul devrait avoir des NIC redondantes connectées à des commutateurs d'accès couche 2 séparés.
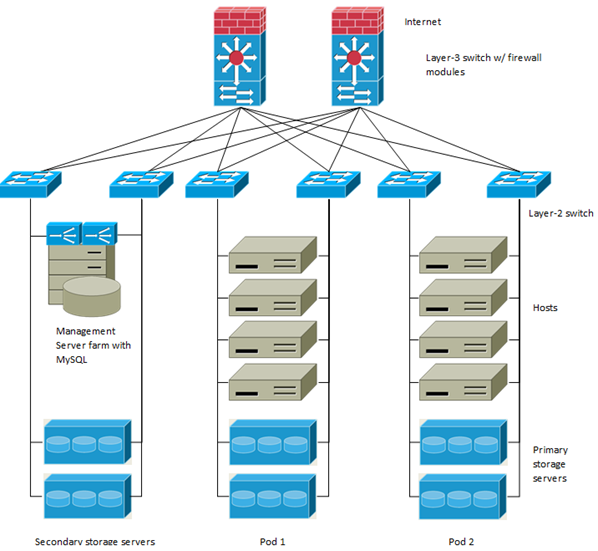
fig7: modèle de déploiement a petite échelle de CloudStack
Pour installer CloudStack nous devons disposer d’un environnement bien préparer. Nous allons donc avoir , le système d’exploitation étant installé, configurer un serveur NFS avec plusieurs types de stockage. Les prérequis sont les suivants:
- Un ordinateur pouvant supporter la virtualisation matérielle.
- Le setup d’installation de CentOS 8.0.1905
- Une connexion internet
Pour tout ce qui suit nous travaillons en environnement virtuel avec virtualbox sous ubuntu.
Avant de commencer, vous devez préparer l'environnement avant d'installer CloudStack. Nous allons passer en revue les étapes pour cette préparation.
À l’aide de l’ISO d’installation CentOS , vous devez l’installer le système sur votre matériel, choisissez l’option d’installation minimale. Les valeurs par défaut seront généralement acceptables pour cette installation. Vous souhaiterez peut-être configurer la configuration du réseau lors de l'installation, en suivant les instructions ci-dessous ou en utilisant une configuration d'accès standard que nous modifierons ultérieurement.
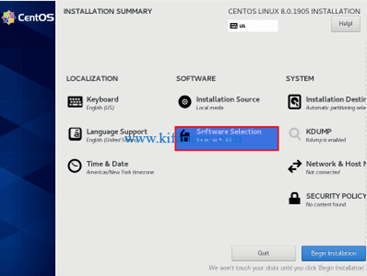
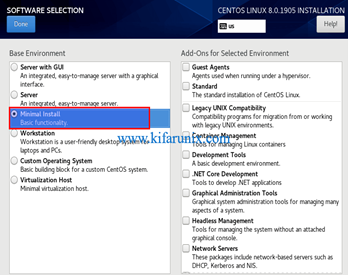
fig 8: Installation de centOS
Une fois cette installation terminée, vous souhaiterez accéder à votre serveur via SSH (si le réseau est configuré) ou des périphériques connectés. Notez que vous ne devez pas autoriser les connexions root à distance dans un environnement de production. Veillez donc à désactiver cette fonctionnalité une fois l'installation et la configuration terminées. Si votre interface réseau a été configurée pour accorder un accès Internet au serveur, il est toujours sage de mettre à jour le système avant de démarrer avec la commande:
# yum -y upgrade
L'interface réseau ne s'affichera pas sur votre matériel et vous devrez le configurer pour qu'il fonctionne dans votre environnement.Avant d’aller plus loin, assurez-vous que «brctl» est installé et disponible:
# yum install bridge-utils -y
Vous devez maintenant vous connecter en console en tant que root. Nous allons commencer par créer le pont que Cloudstack utilisera pour la mise en réseau. Créez et ouvrez le fichier / etc / sysconfig / network-scripts / ifcfg-cloudbr0 et ajoutez les paramètres suivants:
DEVICE=cloudbr0
TYPE=Bridge
ONBOOT=yes
BOOTPROTO=static
IPV6INIT=no
IPV6_AUTOCONF=no
DELAY=5
IPADDR=172.16.10.2
GATEWAY=172.16.10.1
NETMASK=255.255.255.0
DNS1=8.8.8.8
DNS2=8.8.4.4
STP=yes
USERCTL=no
NM_CONTROLLED=no
Enregistrez la configuration et quittez. Nous allons ensuite éditer l’interface pour qu’elle utilise ce pont.Ouvrez le fichier de configuration de votre interface et configurez-le comme suit:
TYPE=Ethernet
BOOTPROTO=none
DEFROUTE=yes
NAME=eth0
DEVICE=eth0
ONBOOT=yes
BRIDGE=cloudbr0
NB :eth0 représentant ici votre interface de Ethernet par défaut.
Maintenant que les fichiers de configuration sont correctement configurés, nous devons exécuter quelques commandes pour démarrer le réseau :
# systemctl enable network
# systemctl restart network
Notez que si vous étiez connecté via SSH, vous serez temporairement déconnecté (~ 5 secondes, en fonction du matériel). Si la déconnexion dure, une erreur de configuration s'est produite.
CloudStack nécessite que le nom d'hôte soit correctement défini. Si vous avez utilisé les options par défaut lors de l'installation, votre nom d'hôte est actuellement défini sur localhost.localdomain. Pour tester cela, nous allons exécuter:
# hostname –fqdn
Normalement l’exécution de cette commande devrait retourner localhost.
Vous pouvez remédier à cette situation en définissant le nom d’hôte en modifiant le fichier /etc/ hosts.
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
172.16.10.2 srvr1.cloud.priv
Après avoir modifié ce fichier, redémarrez le réseau en utilisant:
# systemctl restart network
Maintenant, revérifiez avec la commande hostname –fqdn et assurez-vous qu’elle renvoie une réponse FQDN.
Pour que CloudStack fonctionne correctement, SELinux doit être défini sur permissif. Pour cela, dans le système en cours d'exécution, nous devons exécuter la commande suivante:
# setenforce 0
Pour nous assurer qu'il reste dans cet état, nous devons configurer le fichier / etc / selinux / config afin qu'il reflète l'état permissif, comme indiqué dans cet exemple:
# SELINUX= can take one of these three values:
# enforcing - SELinux security policy is enforced.
# permissive - SELinux prints warnings instead of enforcing.
# disabled - No SELinux policy is loaded.
SELINUX=permissive
# SELINUXTYPE= can take one of these two values:
# targeted - Targeted processes are protected,
# mls - Multi Level Security protection.
SELINUXTYPE=targeted
La configuration NTP est une nécessité pour garder toutes les horloges de vos serveurs cloud synchronisées. Cependant, NTP n'est pas installé par défaut. Nous allons donc installer et configurer NTP à ce stade. L'installation est réalisée comme suit:
# yum -y install ntp
La configuration par défaut réelle convient à nos besoins; nous devons donc simplement l'activer et la configurer pour qu'elle démarre au démarrage de la manière suivante:
# systemctl enable ntpd
# systemctl start ntpd
Nous devons configurer la machine pour utiliser un référentiel de packages CloudStack car les version officielle de ce dernier sont du code source.Pour ajouter le référentiel CloudStack, créez /etc/yum.repos.d/cloudstack.repo et insérez les informations suivantes.
[cloudstack]
name=cloudstack
baseurl=http://download.cloudstack.org/centos/7/4.11/
enabled=1
gpgcheck=0
Notre configuration utilisera NFS pour le stockage principal et secondaire. Nous allons aller de l'avant et configurer deux partages NFS à ces fins. Nous allons commencer par installer nfs-utils.
# yum -y install nfs-utils
Nous devons maintenant configurer NFS pour servir deux partages différents. Ceci est traité relativement facilement dans le fichier / etc / exports. Vous devez vous assurer qu'il contient le contenu suivant:
/ export / secondary * (rw, async, no_root_squash, no_subtree_check)
/ export / primary * (rw, async, no_root_squash, no_subtree_check)
Vous noterez que nous avons spécifié deux répertoires qui n'existent pas (encore) sur le système. Nous allons créer ces répertoires et définir les autorisations correspondantes à l'aide des commandes suivantes:
# mkdir -p /export/primary
# mkdir /export/secondary
Les versions de CentOS 7.x utilisent NFSv4 par défaut. NFSv4 nécessite que le paramètre de domaine corresponde sur tous les clients. Dans notre cas, le domaine est cloud.priv. Veillez donc à ce que le paramètre de domaine défini dans /etc/idmapd.conf ne soit pas commenté et soit défini comme suit: Domain = cloud.priv
Maintenant, vous devez ajouter les valeurs de configuration au bas du fichier / etc / sysconfig / nfs (ou tout simplement supprimer le commentaire et les définir)
LOCKD_TCPPORT=32803
LOCKD_UDPPORT=32769
MOUNTD_PORT=892
RQUOTAD_PORT=875
STATD_PORT=662
STATD_OUTGOING_PORT=2020
Nous devons maintenant désactiver le pare-feu afin qu’il ne bloque pas les connexions. Pour ce faire, utilisez simplement les deux commandes suivantes:
# systemctl stop firewalld
# systemctl disable firewalld
Nous devons maintenant configurer le service nfs pour qu'il démarre au démarrage et le démarre réellement sur l'hôte en exécutant les commandes suivantes:
# systemctl enable rpcbind
# systemctl enable nfs
# systemctl start rpcbind
# systemctl start nfs
Nous allons installer le serveur de gestion CloudStack et les outils environnants.
Installation et configuration de la base de données
Nous allons commencer par installer MySQL et configurer certaines options afin de nous assurer qu'il fonctionne correctement avec CloudStack.
Tout d'abord, étant donné que CentOS 7 ne fournit plus les fichiers binaires MySQL, nous devons ajouter un référentiel:
# wget http://repo.mysql.com/mysql-community-release-el7-5.noarch.rpm
# rpm -ivh mysql-community-release-el7-5.noarch.rpm
# yum -y update
Installez en exécutant la commande suivante:
# yum -y install mysql-server
Maintenant que MySQL est installé, nous devons apporter quelques modifications à la configuration de /etc/my.cnf . Plus précisément, nous devons ajouter les options suivantes à la section [mysqld]:
innodb_rollback_on_timeout=1
innodb_lock_wait_timeout=600
max_connections=350
log-bin=mysql-bin
binlog-format = 'ROW'
Maintenant que MySQL est correctement configuré, nous pouvons le démarrer et le configurer pour démarrer au démarrage comme suit:
# systemctl enable mysqld
# systemctl start mysqld
Installez le connecteur Python MySQL en utilisant le référentiel officiel des packages MySQL. Créez le fichier /etc/yum.repos/mysql.repo avec le contenu suivant:
[mysql-connectors-community]
name=MySQL Community connectors
baseurl=http://repo.mysql.com/yum/mysql-connectors-community/el/$releasever/$basearch/
enabled=1
gpgcheck=1
Importer la clé publique GPG depuis MySQL:
rpm --import http://repo.mysql.com/RPM-GPG-KEY-mysql
Installer mysql-connector en tapant:
#yum install mysql-connector-python
Nous allons maintenant installer le serveur de gestion. Nous faisons cela en exécutant la commande suivante:
# yum -y install cloudstack-management
Avec l'application elle-même installée, nous pouvons maintenant configurer la base de données. Pour ce faire, utilisez la commande et les options suivantes:
# cloudstack-setup-databases cloud:password@localhost –deploy-as=root
Lorsque ce processus est terminé, un message du type «CloudStack a initialisé la base de données avec succès» devrait s'afficher. Maintenant que la base de données a été créée, nous pouvons passer à la dernière étape de la configuration du serveur de gestion en lançant la commande suivante:
# cloudstack-setup-management
CloudStack utilise un certain nombre de machines virtuelles système pour fournir une fonctionnalité permettant d'accéder à la console des machines virtuelles, fournissant divers services de réseau et gérant divers aspects du stockage. Cette étape permettra d’acquérir ces images système prêtes à être déployées lorsque nous amorcerons votre cloud.
Nous devons maintenant télécharger le modèle de machine virtuelle système et le déployer sur le partage que nous venons de monter. Le serveur de gestion comprend un script permettant de manipuler correctement les images du système virtuel. On lance son exécution comme suit:
/ usr / share / cloudstack-common / scripts / storage / secondaire / cloud-install-sys-tmplt -m / export / secondary -u http://download.cloudstack.org/systemvm/4.11/systemvmtemplate-4.11.2- kvm.qcow2.bz2 -h kvm -F
Ceci conclut notre configuration du serveur de gestion. Nous devons toujours configurer CloudStack, mais nous le ferons après avoir configuré notre hyperviseur.
L'installation de l'agent KVM est simple avec une seule commande, mais nous devrons ensuite configurer quelques éléments. La commande est la suivante :
# yum -y install cloudstack-agent
Nous avons deux parties différentes de KVM à configurer, libvirt et QEMU. Nous devons éditer la configuration QEMU VNC. Pour ce faire, éditez /etc/libvirt/qemu.conf et assurez-vous que la ligne suivante est présente et non commentée.
vnc_listen=0.0.0.0
CloudStack utilise libvirt pour gérer les machines virtuelles. Par conséquent, il est essentiel que libvirt soit configuré correctement. Libvirt est une dépendance de cloud-agent et devrait déjà être installé.
- Pour que la migration soit opérationnelle, libvirt doit rechercher les connexions TCP non sécurisées. Nous devons également désactiver la tentative de libvirts d’utiliser la publicité DNS multidiffusion. Ces deux paramètres sont dans /etc/libvirt/libvirtd.conf . Définissez les paramètres suivants:
listen_tls = 0
listen_tcp = 1
tcp_port = "16509"
auth_tcp = "none"
mdns_adv = 0
- Activer «listen_tcp» dans libvirtd.conf ne suffit pas, nous devons également modifier les paramètres. Nous devons également modifier /etc/sysconfig / libvirtd, décommentez la ligne suivante:
#LIBVIRTD_ARGS="—listen"
- Redémarrer libvirt en tapant la commande suivante:
# systemctl restart libvirtd
Par souci d’exhaustivité, vous devez vérifier si KVM fonctionne correctement sur votre ordinateur. En tapant dans une Console:
lsmod | grep kvm
Ceci conclut notre installation et la configuration de KVM, et nous allons maintenant passer à l’utilisation de l’UI CloudStack pour la configuration réelle de notre cloud.
Comme nous l'avons indiqué précédemment, nous utiliserons des groupes de sécurité pour assurer l'isolation, ce qui implique par défaut d'utiliser un réseau à couche 2 plate. Cela signifie également que la simplicité de notre configuration nous permet d'utiliser l'installateur rapide.
Pour accéder à l'interface Web de CloudStack, il vous suffit de pointer votre navigateur sur http://172.16.10.2:8080/client. Le nom d'utilisateur par défaut est 'admin' et le mot de passe par défaut, 'password'. Vous devriez voir un écran de démarrage vous permettant de choisir plusieurs options pour configurer CloudStack. Vous devez choisir l'option Continuer avec la configuration de base.
Une zone est la plus grande entité organisationnelle de CloudStack - et nous en créerons une, ce devrait être l'écran que vous voyez maintenant devant vous. Et pour nous, il y a 5 informations dont nous avons besoin.
Nom - nous allons définir cela comme toujours descriptif 'Zone1' pour notre cloud.
- Public DNS 1 - nous allons définir cela 8.8.8.8pour notre cloud.
- Public DNS 2 - nous allons définir cela 8.8.4.4pour notre nuage.
- DNS1 interne - nous allons également définir cela 8.8.8.8pour notre nuage.
- DNS2 interne - nous allons également définir cela 8.8.4.4pour notre nuage.
Maintenant que nous avons ajouté une zone, il suffit d'ajouter quelques éléments supplémentaires pour configurer le cluster.
- Name - Nous utiliserons Cluster1
- Hypervisor – Choisissez KVM
Vous devriez être invité à ajouter le premier hôte à votre cluster à ce stade. Quelques informations sont nécessaires.
- Hostname - nous utiliserons l'adresse IP 172.16.10.2 car nous n'avons pas configuré de serveur DNS.
- Username - nous allons utiliser root
- Password - entrez le mot de passe du système d'exploitation pour l'utilisateur root.
Avec votre cluster maintenant configuré - vous devriez être invité à fournir des informations sur le stockage principal. Choisissez NFS comme type de stockage, puis entrez les valeurs suivantes dans les champs:
- Name - Nous utiliserons Primary
- Server – Nous utiliserons l’adresse IP: 172.16.10.2
- Path - Bien définir /export/primary comme le chemin que nous utilisons
S'il s'agit d'une nouvelle zone, des informations sur le stockage secondaire vous seront demandées. Remplissez-la comme suit:
- NFS server - Nous utiliserons l'adresse IP 172.16.10.2
- Path Nous allons utiliser - /export/secondary
Conclusion
En somme, face à l’évolution sans cesse grandissante des technologies numérique, des mentalités, et de l’internet, le cloud computing grâce aux principes de la virtualisation s’impose de plus en plus comme une alternative sérieuse a l’offre traditionnelle des services. Ainsi, ce dernier propose énormément de services (solutions cloud) qui se repartissent en trois couches à savoir IaaS(Infrastructure as a service), PaaS(Plateforme as a Service), SaaS(Software as a Service). De nombreux logiciels ont notamment vu le jour depuis l’avènement de ce concept de cloud computing, proposant des interfaces pour faciliter la mise en place de solutions cloud(services cloud) à l’instar de CloudStack qui était le sujet de ce document. Ce dernier étant open-source, il est sans cesse mis à jour afin de rendre de plus en plus facile la mis en place de solution clouds d’infrastructure(IaaS). CloudStack permet aussi de pouvoir géré les clouds public et priver et les solution déployer via ce logiciel suivent le modèle de déploiement standard d’une solution cloud d’infrastructure qui se décline en la définition de régions, de zones, de pods, de clusters, d’hotes, des unités de stockages principales et secondaires, ainsi que des réseaux physiques liant les entités d’une zone.
Bibliographie
1.https://docs.cloudstack.apache.org/en/latest/quickinstallationguide/qig.html
3.https://kifarunix.com/install-centos-8-on-virtualbox/
4.https://www.centos.org/download/
5.https://fr.wikipedia.org/wiki/Serveur_de_stockage_en_r%C3%A9seau

? Salut, moi c’est PandaCodeur !
Un jour, j’ai oublié un point-virgule…
et toute ma forêt a planté ?
Mais grâce à Pandacodeur, j’ai appris de mes erreurs !
? Sur Pandacodeur, tu peux :
✔ apprendre la programmation de façon pratique
✔ t’entraîner avec des quiz interactifs
✔ comprendre grâce à des exercices corrigés
✔ te préparer efficacement à l’examen
Prêt à coder sans paniquer ? ?
Questions / Réponses
Ajouter un commentaire